ใคร ๆ ก็รู้ว่าโดยทั่วไป Decision Tree นั้นดีกว่า Logistic Regression แต่ทำไมล่ะ

สมมติว่าคุณได้รับคำสั่งจากหัวหน้าให้สร้าง Machine Learning ง่าย ๆ ขึ้นมาสักตัวเพื่อมาจำแนกข้อมูลที่มีออกเป็นกลุ่ม ๆ
คุณเริ่มต้นจากการไปเสิร์ชดูว่ามีโมเดลอะไรบ้างที่ทำ classification ได้ แล้วก็เจอว่ามีอยู่ 2 ตัวที่มักจะโผล่ขึ้นมาเป็นชื่อแรก ๆ นั่นคือ Logistic Regression และ Decision Tree
แต่ตัวไหนดีกว่ากันล่ะ?
ลองเสิร์ชต่ออีกนิด มีบทความเขียนเรื่องนี้ไว้เยอะเลย อย่างเช่นบทความของคุณคนนี้
จากการลองดูหลาย ๆ เว็บ บทความส่วนใหญ่พูดเป็นเสียงเดียวกันว่า
โดยทั่วไป Decision Tree นั้นดีกว่า Logistic Regression โดยเฉพาะกับข้อมูลที่ซับซ้อนไม่เป็นเส้นตรง
แต่คำถามคือ ทำไมถึงเป็นแบบนั้น
ด้วยความที่คุณอ่านเพจคณิตศาสตร์อย่างที่ควรจะเป็นมาบ้าง คุณจึงรู้ว่าเพื่อที่จะตอบคำถามนี้ คุณต้องแงะเข้าไปดูว่ากลไกการทำงานของทั้งสองตัวนั้นเป็นยังไง
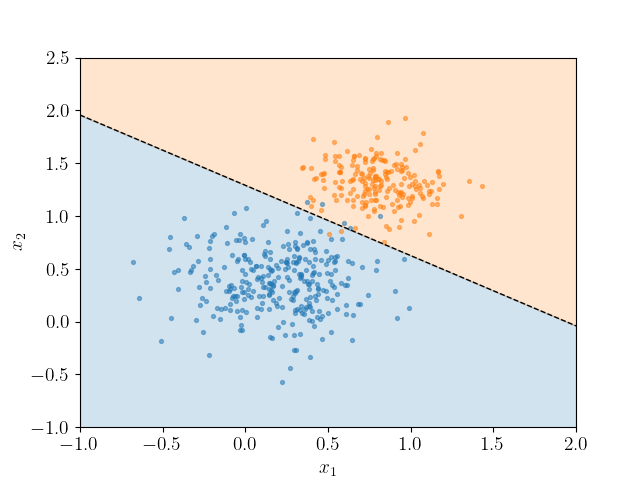
คุณเจอว่า Logistic Regression แบบพื้นฐานนั้นจะลากเส้นตรงเพื่อแยกกลุ่มข้อมูล โดยพยายามหาเส้นแบ่งที่ทำให้ความน่าจะเป็นของการอยู่ในกลุ่มใดกลุ่มหนึ่งดีที่สุด
ส่วน Decision Tree นั้นแยกข้อมูลด้วยการตั้งคำถามลำดับชั้น เช่น “ค่า A > 10 หรือไม่” แล้วตัดสินใจตามเส้นทางของคำตอบเหล่านั้น
ซึ่งดูเป็นสองวิธีที่แตกต่างกันโดยสิ้นเชิง ถ้าอย่างนั้นเราจะบอกได้ยังไงว่าวิธีไหนดีกว่ากันล่ะ
คืออย่างงี้ฮะ การมอง Decision Tree ในแง่ของการตั้งคำถามแล้วแยกลงไปเรื่อย ๆ เนี่ย มันเป็นวิธีที่เห็นภาพและเข้าใจง่ายก็จริง แต่ถ้าเราต้องการเอาไปเปรียบเทียบกับวิธีอื่น อย่าง Logistic Regression มันก็จะเริ่มติดปัญหา เพราะโมเดลหนึ่งดูเป็นลำดับของคำถาม ส่วนอีกอันเป็นการใช้เส้นมาแบ่งพื้นที่ของข้อมูลออกเป็นโซน
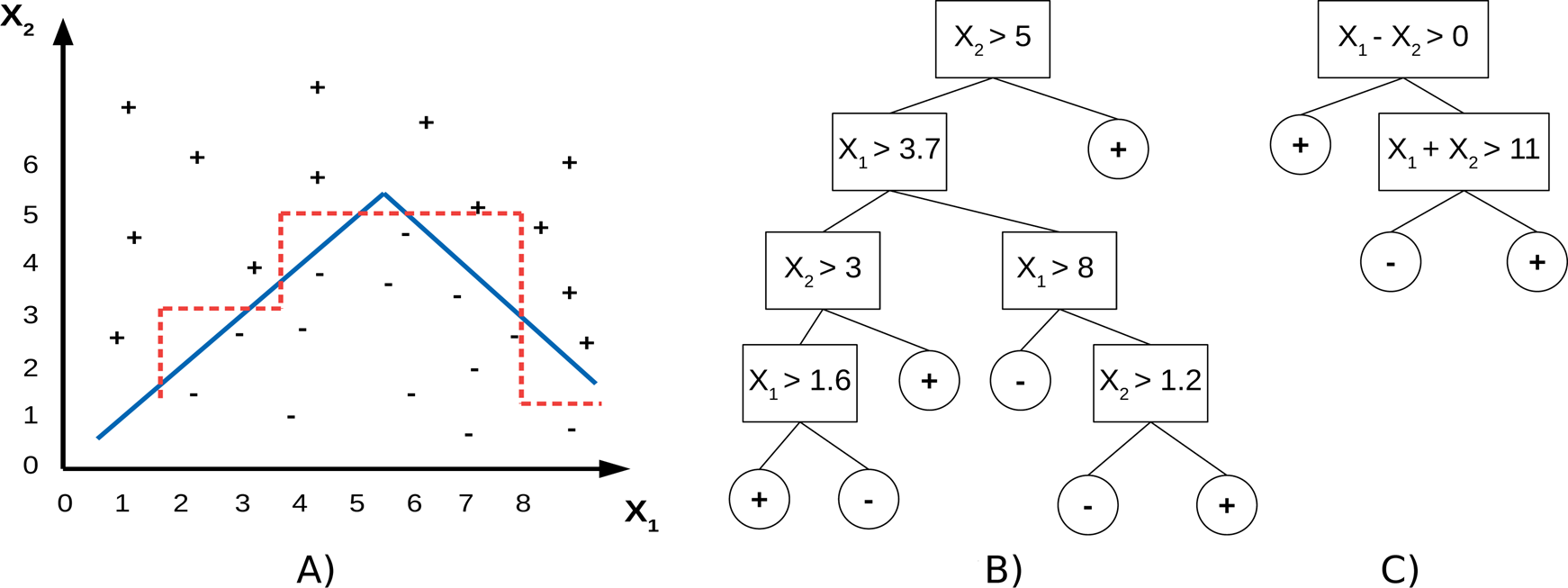
แต่ถ้าเรามองให้ลึกลงไปอีกนิด ว่าที่จริงแล้ว Decision Tree มันก็คือแบ่งพื้นที่ของข้อมูลออกเป็นโซนเหมือนกันนี่นา
เช่น ถ้าคุณมีข้อมูลอยู่บนระนาบสองมิติ การตั้งคำถามของ Decision Tree นั้นคือการลากเส้นตรงในแนวตั้งหรือแนวนอนเพื่อแบ่งพื้นที่นั้นออกเป็นช่อง ๆ ตามคำถามที่มันตั้ง
เช่นการถามว่า “X1 < 2 ไหม” ก็คือลากเส้นตั้งที่ X1 = 2 แล้วแบ่งโซนซ้ายขวา หรือการถามว่า “X2 < 2.5 ไหม” ก็คือการลากเส้นนอนที่ X2 = 2.5 แล้วแบ่งบนล่าง เพื่อตัดพื้นที่ออกเป็นช่อง ๆ ไปเรื่อย ๆ
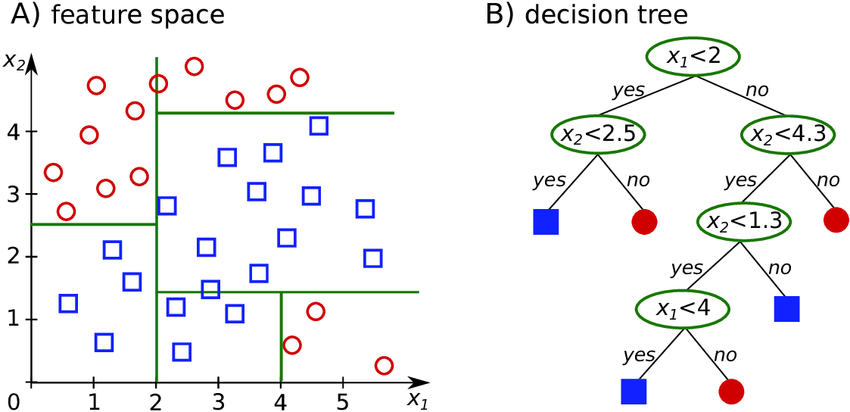
ในมุมนี้ เราจะเห็นว่า Decision Tree กำลังแบ่งพื้นที่ของข้อมูลเช่นเดียวเหมือนกัน จะต่างตรงที่ Logistic Regression ใช้เส้นเฉียง ๆ ในขณะที่ Decision Tree ใช้เส้นที่ตั้งฉากกับแกนหลายเส้นมาประกอบกัน
ด้วยเหตุนี้เอง Decision Tree จึงมักทำงานได้ดีในกรณีที่รูปแบบของข้อมูลมีความซับซ้อนเกินกว่าจะใช้เส้นตรงเส้นเดียวตัดได้ เพราะมันสามารถค่อย ๆ ตัดข้อมูลออกเป็นชิ้นเล็ก ๆ ตามแต่ละเงื่อนไขที่กำหนดไว้ในแต่ละโหนดของต้นไม้
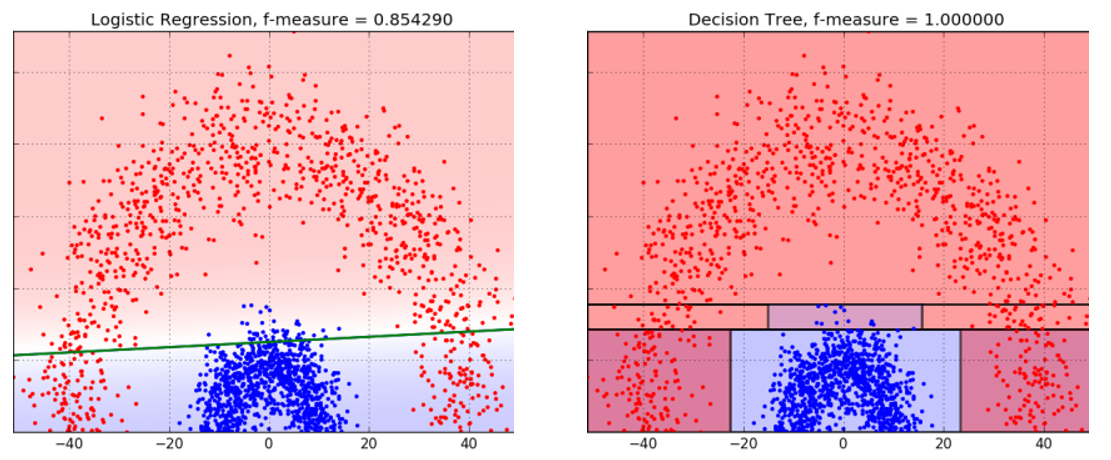
แต่ในทางกลับกัน หากข้อมูลมีรูปแบบที่เรียบง่าย เช่น แบ่งได้ด้วยเส้นตรงเดียวชัดเจน Decision Tree กลับอาจต้องใช้การแบ่งหลายครั้ง สร้างเงื่อนไขที่ซับซ้อนโดยไม่จำเป็น เพียงเพื่อพยายามดัดเส้นแบ่งให้ออกมาเฉียง ๆ ตามข้อมูลจริง ซึ่งในกรณีแบบนี้ Logistic Regression อาจให้ผลลัพธ์ที่ดีกว่า เพราะมันสามารถใช้เส้นเฉียงตรง ๆ ได้เลยตั้งแต่ต้น
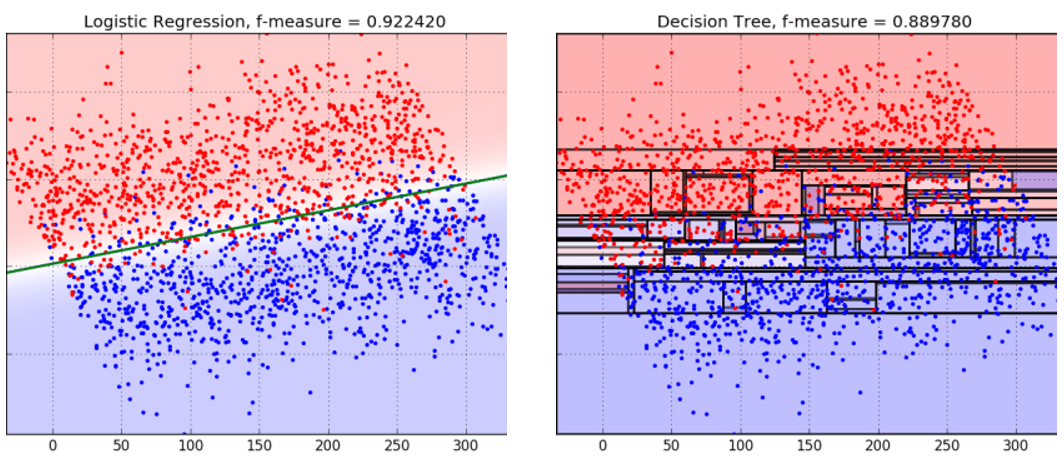
และด้วยกลไกที่เปิดให้เราสามารถตั้งคำถามซ้ำ ๆ แบบละเอียดมากขึ้นเรื่อย ๆ Decision Tree จึงมักเผชิญกับปัญหา overfitting ได้ง่าย โดยเฉพาะเมื่อเราอนุญาตให้ต้นไม้เติบโตลึกเกินไป การแตกกิ่งก้านมากเกินไปอาจทำให้โมเดลตอบสนองกับ noise หรือจุดข้อมูลที่ไม่ปกติจนเกินความจำเป็น
นอกจากความเข้าใจกลไกการทำงานของโมเดลแต่ละตัวนั้นจะช่วยให้เราสามารถเลือกใช้โมเดลได้อย่างเหมาะสมกับงานของเราแล้ว มันยังเป็นจุดเริ่มต้นของการพัฒนาโมเดลใหม่ ๆ ที่ซับซ้อนขึ้น อย่างเช่น Oblique Tree ที่ต่อยอดไอเดียจาก Decision Tree เดิม โดยแทนที่แต่ละโหนดจะตั้งคำถามแบบง่าย ๆ เช่น “X1 < 2 ไหม” มันสามารถตั้งคำถามที่ซับซ้อนขึ้น เช่น “1.2X1 + 0.8X2 < 3 ไหม” ซึ่งคือการลากเส้นเฉียงในการแบ่งแทน ซึ่งช่วยให้โมเดลมีความยืดหยุ่นในการจำแนกรูปแบบของข้อมูลมากขึ้น และลดการต้องใช้โหนดจำนวนมากเพียงเพื่อพยายามดัดเส้นแบ่งให้โค้งไปตามข้อมูล
แน่นอนว่า ความยืดหยุ่นที่เพิ่มขึ้นก็มาพร้อมกับความซับซ้อนที่เพิ่มตามไปด้วย ทั้งในแง่ของเวลาที่ต้องใช้ในการคำนวณ และการตีความผลลัพธ์ เพราะโมเดลจะไม่ใช่ต้นไม้ง่าย ๆ ที่เราสามารถไล่อ่านตามกิ่งก้านได้เหมือนเดิม
โมเดลยุคใหม่ ๆ ที่เราใช้กันทุกวันนี้ก็เกิดจากการทำความเข้าใจโมเดลเก่า ๆ และพยายามอุดรอยรั่วจากโมเดลเหล่านั้นทั้งสิ้น
ทั้งหมดนี้สะท้อนให้เห็นว่าการเข้าใจกลไกทางคณิตศาสตร์ที่อยู่เบื้องหลัง Machine Learning ต่าง ๆ นั้นสำคัญมาก เพราะมันเป็นพื้นฐานสำคัญที่จะพาเราไปไกลกว่าการเลือกโมเดลสำเร็จรูปมาใช้ แต่ไปสู่การปรับปรุงและออกแบบโมเดลให้เข้ากับโจทย์ของเราจริง ๆ ได้ในอนาคต
และสำหรับใครที่ต้องการเข้าใจคณิตศาสตร์ที่อยู่เบื้องหลังโมเดล Machine Learning ตัวต่าง ๆ แบบในบทความนี้ ไม่ว่าจะเป็น Logistic Regression ไปจนถึง Tree-based Models และ Neural Network
ผมขอแนะนำคอร์ส 'ML with Equations' โดย อุ๋ย ภคภูมิ สารพัฒน์ นักวิทยาการข้อมูลและเจ้าของช่อง PakapongZa ที่จะพาทุกคนไปทำความรู้จักแนวคิดทางคณิตศาสตร์ของโมเดล Supervised Learning แบบต่าง ๆ เพื่อไม่ให้แค่ใช้ model.fit ได้ แต่ต้องใช้ให้เป็น
ดูตัวอย่างการสอน และสมัครเพื่อเข้าเรียนได้ทางนี้เลยฮะ https://unfoldthedice.onlinecoursehost.com/courses
เอกสารอ้างอิง
https://www.displayr.com/decision-trees-are-usually-better-than-logistic-regression/
https://gustavwillig.medium.com/decision-tree-vs-logistic-regression-1a40c58307d0
https://scipython.com/blog/plotting-the-decision-boundary-of-a-logistic-regression-model/
https://blog.bigml.com/2016/09/28/logistic-regression-versus-decision-trees/
https://docs.neurodata.io/treeple/v0.7/modules/supervised_tree.html