ทำไม Logistic Regression ถึงได้ชื่อว่า Regression ทั้ง ๆ ที่มันเอาไว้ทำ Classification ด้วยซ้ำ
ผมเชื่อว่าคนที่คลุกคลีกับ Machine Learning น่าจะต้องเคยข้องเกี่ยว Logistic Regression มาไม่มากก็น้อย เพราะเมื่อไรก็ตามที่เราต้องการแก้ปัญหา Classification เจ้า Logistic Regression ก็มักจะเป็นโมเดลแรก ๆ ที่ถูกนึกถึง
ในความเป็นจริงแล้ว Logistic Regression ไม่ได้ถูกใช้แค่ในวงการ Machine Learning เท่านั้น แต่มันยังถูกใช้ในวงการอื่น ๆ อีกมากมาย เช่น ในวงการแพทย์ก็มีการใช้ Logistic Regression ศึกษาปัจจัยเสี่ยงที่ส่งผลให้เกิดโรคต่าง ๆ หรือในฝั่งเศรษฐศาสตร์ก็มีการใช้ Logistic Regression ศึกษาปัจจัยที่ส่งผลต่อพฤติกรรมของผู้บริโภคเช่นกัน
ใครที่ไม่คุ้นกับศัพท์ทาง Machine Learning ผมเล่าให้ฟังคร่าว ๆ ก่อนว่าในบรรดาปัญหาทาง Machine Learning นั้น มีอยู่สองปัญหาที่เราเจอบ่อย ๆ อันแรกคือ Classification ซึ่งคือการทำนายกลุ่ม เช่นทำนายว่าคนไข้เป็นโรคหรือไม่เป็น ภาพนี้เป็นหมาหรือแมว กับปัญหา Regression ซึ่งคือการทำนายค่า เช่นพรุ่งนี้อุณหภูมิจะเป็นเท่าไร หรือราคาบ้านหลังนี้น่าจะเป็นเท่าไร
และ Logistic Regression เป็นหนึ่งในเครื่องมือในการทำแก้ปัญหา Classification ที่ง่ายที่สุด คำถามคือ แล้วทำไมเราถึงเรียกมันว่า Logistic Regression ล่ะ ถ้ามันเอาไว้ใช้ทำ Classification ทำไมเราถึงไม่เรียกโมเดลนี้ว่า Logistic Classification ล่ะ
เพื่อที่จะตอบคำถามนี้ เราต้องไปแงะดูว่าจริง ๆ แล้ว Logistic Regression มันคือการทำอะไร
สำหรับกรณีที่ง่ายที่สุด ถ้าเราต้องการทำ Classification อะไรสักอย่างด้วยข้อมูลเพียงค่าเดียว แปลว่าข้อมูลที่อยู่ในมือเราจะมีหน้าตาเป็นคู่อันดับ (X,y) เมื่อ X คือค่าที่เราจะเอาไปใช้ทำนาย ส่วน y คือกลุ่มที่มันอยู่ ซึ่งคือค่าที่เราต้องการทำนาย ในที่นี้ให้มีแค่สองกลุ่มแล้วกัน คือกลุ่ม 0 กับกลุ่ม 1
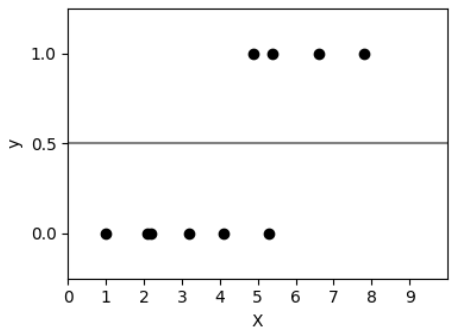
จากภาพจะเห็นค่า สำหรับ X ที่มีค่าน้อย ๆ เราจะทำนายว่า y=0 และสำหรับ X ที่มีค่ามาก ๆ เราจะทำนายว่า y=1 แต่เราจะแบ่งมันตรงไหนดีล่ะ
ถ้าเราใช้ Linear Regression มาพยายาม fit กับข้อมูลชุดนี้ ผลที่เราได้ก็จะออกมาเป็นเส้นตรงเส้นหนึ่งที่ลากเฉียง ๆ ผ่านข้อมูลแต่ละกลุ่ม แต่เส้นนี้ก็ไม่ได้บอกอะไรเราเท่าไร
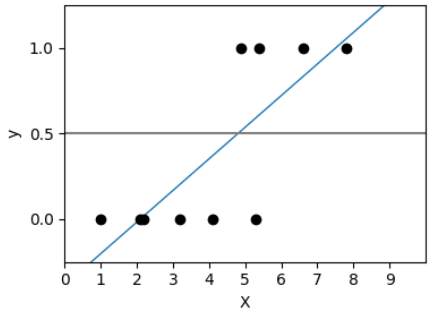
ดังนั้นถ้าเราเปลี่ยนใหม่ ไม่ใช้เส้นตรงมาทำ Regression แต่เปลี่ยนไปใช้เส้นโค้งที่หน้าตาเหมือนตัว S มาทำ Regression แทน นี่คือสิ่งที่เราได้ฮะ
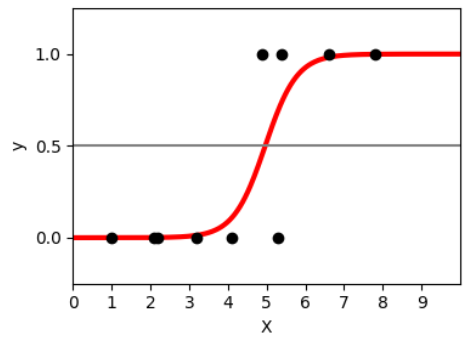
เส้นโค้งเส้นนี้ถูกเรียกว่า Logistic Function หรืออีกชื่อที่บางคนอาจจะคุ้นเคยคือ Sigmoid Function เส้นโค้งนี้ถูกศึกษาครั้งแรกโดยคุณ Pierre François Verhulst นักคณิตศาสตร์ชาวเบลเยียมระหว่างที่เขากำลังศึกษาการเติบโตของจำนวนประชากรในสหรัฐอเมริกาในช่วงศตวรรษที่ 19 และคุณ Verhulst ก็เป็นคนที่ตั้งชื่อให้ฟังก์ชันนี้ว่า Logistic Function ด้วย ในช่วงเวลาใกล้เคียงกัน Logistic Function ก็ถูกค้นพบโดยคุณ Friedrich Wilhelm Ostwald นักเคมีชาวเยอรมันระหว่างที่เขากำลังศึกษาการเร่งปฏิกิริยาอัตโนมัติ ความจริงแล้วมีเรื่องการค้นพบ Logistic Function แอบแซ่บนิดหน่อย มีการแย่งกันเคลมความเป็นคนแรกที่ค้นพบกันอยู่ประมาณนึง ใครสนใจผมแปะลิงก์ไว้ในอ้างอิงแล้ว
ลักษณะเด่นสำคัญของ Logistic Function ก็คือมันเป็นฟังก์ชันเพิ่ม และค่าของมันอยู่ในช่วง 0 ถึง 1 ดังนั้นค่าบนเส้นสีแดงของ Logistic Function จึงมองได้ว่าเป็นความน่าจะเป็นที่ข้อมูลจะอยู่ในกลุ่มที่ 1
อย่างตัวอย่างในรูปข้างบนจะเห็นว่า ถ้า x มีค่าน้อยกว่า 3 เราแทบจะมั่นใจ 100% ว่าข้อมูลต้องอยู่ในกลุ่ม 0 ในขณะที่ถ้า x มีค่ามากกว่า 7 เราก็แทบจะมั่นใจอีกเช่นกันว่าข้อมูลต้องอยู่ในกลุ่ม 1 ชัวร์ ๆ ส่วนระหว่าง 3 ถึง 7 นั้นก็เป็นบริเวณที่เราไม่แน่ใจ ด้วยความน่าจะเป็นที่ต่างกันไปตามเส้นสีแดง ซึ่งถ้าอยากฟันธงลงไปจริง ๆ ว่ามันอยู่คลาสไหน เราก็จะต้องตั้งเกณฑ์ขึ้นมา เช่นถ้าเส้นสีแดงเกิน 0.5 เราจะสรุปว่ามันอยู่กลุ่ม 1 ถ้าต่ำกว่าก็อยู่กลุ่ม 0 ไป แบบนี้ก็ได้
พูดถึง Logistic Function มาตั้งนาน ยังไม่เคยให้ดูสมการเลยสักที นี่คือสมการของมันฮะ เห็นไหมว่ามันคือการพยายามทำนายความน่าจะเป็น P(X) ด้วยค่า X โดยมีพารามิเตอร์สองตัวคือ β₀ กับ β₁ นั่นเอง
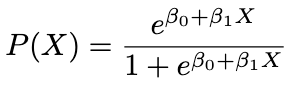
ซึ่งถ้าหากเราจัดรูปฟังก์ชันโลจิสติกต่ออีกนิดหน่อย เราจะได้
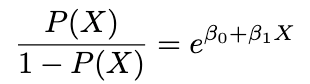
โดยเราเรียกค่าทางซ้ายมือของสมการว่า odds ฮะ แต่เราจะไม่หยุดแค่นี้ ถ้าหากเรา take log ทั้งสองฝั่งของสมการ เราจะได้
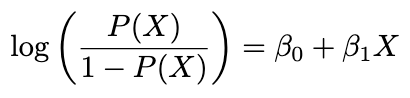
เรียกค่าทางซ้ายมือของสมการว่า Log Odds หรือว่า Logit
ผลที่ได้คือ ตอนนี้สมการมันกลายเป็น Linear Regression แบบที่เราคุ้นเคยเป๊ะเลย เพียงแค่ทางซ้ายมือของเรากลายเป็นค่า Log Odds นั่นหมายความว่าสิ่งที่เราทำจริง ๆ มันคือการใช้ Linear Regression เพื่อมาประมาณค่า Log Odds นั่นเอง
นี่จึงเป็นที่มาว่าทำไมเราถึงเรียกว่า Logistic Regression แทนที่จะเรียกว่า Classification เพราะแม้เป้าหมายปลายทางของเราคือการทำ Classification แต่สิ่งเราทำจริง ๆ เบื้องหลังนั้นคือการทำ Regression ด้วย Logistic Function ต่างหาก แล้วค่อยเอาผลการทำ Regression นั้นไปตั้งเกณฑ์เพื่อแยกเป็นกลุ่ม ๆ อีกที
ความจริงแล้วการรู้คณิตศาสตร์ที่อยู่เบื้องหลัง Logistic Regression นั้น นอกจากจะทำให้เราเข้าใจที่มาของชื่อของมันแล้ว ยังทำให้เราสามารถตีความผลลัพธ์ที่ได้จากโมเดลได้อย่างถูกต้องอีกด้วย เข้าใจว่าพารามิเตอร์ที่คำนวณออกมาได้แต่ละตัวนั้นหมายถึงอะไร ไปจนถึงการเข้าใจเรื่องค่าความน่าจะเป็นที่ทำนายออกมา ซึ่งจะช่วยให้การวิเคราะห์ข้อมูลมีความลึกซึ้งและมีเหตุผลมากขึ้น ไม่ใช่โมเดลมันบอกอะไรมาก็เชื่อไปตามนั้นเฉย ๆ เลย
และสำหรับใครที่ต้องการเข้าใจคณิตศาสตร์ที่อยู่เบื้องหลังโมเดล Machine Learning ตัวต่าง ๆ แบบในบทความนี้ ไม่ว่าจะเป็น Logistic Regression ไปจนถึง Tree-based Models และ Neural Network ผมขอแนะนำคอร์ส 'ML with Equations' โดย คุณอุ๋ย ภคภูมิ สารพัฒน์ นักวิทยาการข้อมูลและเจ้าของช่อง PakapongZa ที่จะพาทุกคนไปทำความรู้จักแนวคิดทางคณิตศาสตร์ของโมเดล Supervised Learning แบบต่าง ๆ เพื่อไม่ให้แค่ใช้ model.fit ได้ แต่ต้องใช้ให้เป็น
โดยสามารถดูรายละเอียดได้ทางนี้เลยฮะ https://unfoldthedice.onlinecoursehost.com/courses
เอกสารอ้างอิง
https://papers.tinbergen.nl/02119.pdf
https://www.mastersindatascience.org/learning/machine-learning-algorithms/logistic-regression/
https://bpb-us-w2.wpmucdn.com/sites.wustl.edu/dist/1/2391/files/2024/06/CIRC-D-24-00044_Prevalence_Final-Proof-to-News-Media.pdf
https://www.researchgate.net/profile/Justine-Mbukwa/publication/373050357_The_adoption_of_mobile_financial_services_in_Tanzania_The_application_of_logit_model/links/65e85bbae7670d36ab00b0be/The-adoption-of-mobile-financial-services-in-Tanzania-The-application-of-logit-model.pdf