ทำไมเราถึงจะถูก 'การคูณเมทริกซ์' แย่งงาน
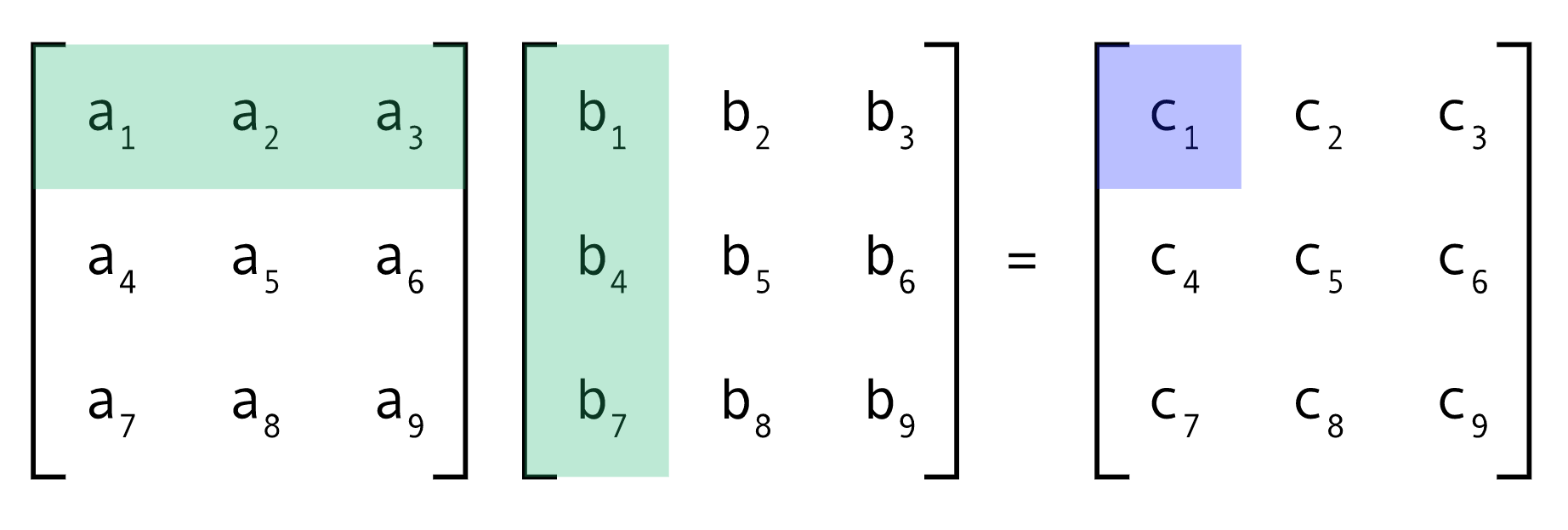
ทุกครั้งที่ผมต้องพูดถึงความสำคัญของเมทริกซ์ โดยเฉพาะอย่างยิ่งเรื่องการคูณ ตัวอย่างที่ยกประจำก็หนีไม่พ้นเรื่องแอปพลิเคชันแต่งภาพ การแปลงข้อมูล การเข้ารหัส หรือไม่ก็เรื่องเมทริกซ์การเปลี่ยนแปลงสถานะ
แต่นี่มัน 2025 แล้ว และผมคิดว่ามีตัวอย่างที่ใหม่กว่า ใกล้ตัวกว่า ใช้อยู่ทุกวันมากกว่า ทรงพลังกว่า และอย่างที่มีคนทำ meme ไว้ว่า มันกำลังจะแย่งงานเราทำ
ใช่ฮะ ผมกำลังพูดถึงพวก generative AI อย่าง ChatGPT หรือ Gemini หรือตัวไหนก็ตามที่คุณใช้อยู่ และใช่ฮะ จริง ๆ แล้วสิ่งที่เป็นหัวใจของ AI สุดฉลาดล้ำพวกนี้นั้นไม่ใช่อะไรเลยนอกจากการคูณเมทริกซ์ ที่เราเรียนกันมาตั้งแต่ ม.4 นั่นแหละ
ผมเริ่มแบบนี้ฮะ คือโครงสร้างการทำงานของ AI ส่วนใหญ่ที่เราใช้ ๆ กันเนี่ยมันเหมือนกันหมดนั่นแหละ คือรับ input บางอย่าง คิด ๆๆๆๆ แล้วก็ส่ง output บางอย่างออกมา
นึกถึงพวก face recognition ก็ได้ ในกรณีนี้ input ของมันก็คือรูปหน้าเรา ส่วน output คือบอกว่าหน้านี้เป็นหน้าของใคร อะไรประมาณนี้
ChatGPT หรือ Gemini ก็ทำงานแบบนี้เหมือนกัน คือมันรับข้อความที่เราพิมพ์เข้าไป ซึ่งเราเรียกมันว่า prompt แล้วก็ส่ง output ออกมาเป็นคำตอบ เช่นเราพิมพ์ถามไปว่า
'เสี่ยหนูอายุเท่าไร'
นี่คือ input และเมื่อมันตอบกลับมาว่า
'ในปี พ.ศ. 2568 เขาอายุ 59 ปี'
ก็คือ output นั่นเอง
สรุปคือ AI พวกนี้มันก็จะต้องอ่านข้อความที่เป็นคำถาม ทำความเข้าใจ และสร้างคำตอบขึ้นมา แล้วการคูณเมทริกซ์เข้ามาเกี่ยวอะไร
ประเด็นของเรื่องนี้ก็คือ คอมพิวเตอร์มันไม่ได้เห็นคำแต่ละคำเป็นคำเหมือนกับที่มนุษย์อย่างเราเห็นน่ะสิครับ แต่มันเห็นเป็นเวกเตอร์ เวกเตอร์ที่หมายถึงชุดของตัวเลขเรียง ๆ กันในหลายมิติน่ะครับ
กระบวนการแปลงคำศัพท์ให้อยู่ในรูปเวกเตอร์นั้นเรียกว่า word embedding หรือ word vectorization ซึ่งถ้าเล่าละเอียด ๆ น่าจะยาว เอาเป็นว่า คำหนึ่งคำ กลายเป็นเวกเตอร์หนึ่งเวกเตอร์
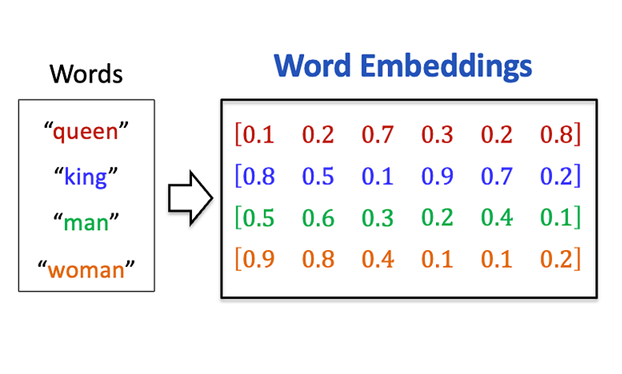
ความพิเศษของการทำ word embedding ก็คือ แม้จากภาพจะดูเหมือนว่าคำศัพท์ต่าง ๆ จะถูกแปลงเป็นเวกเตอร์แบบมั่ว ๆ แต่ความจริงแล้วมันไม่ได้มั่ว เวกเตอร์เหล่านี้ถูกสร้างขึ้นโดยรักษาสมบัติที่ว่า คำที่มีความหมายใกล้เคียงกัน ควรจะถูกแสดงด้วยเวกเตอร์ที่คล้ายกัน
เช่นเวกเตอร์ของคำว่า 'ราชินี' ก็ควรจะคล้ายกับคำว่า 'ราชา' มากกว่าที่มันคล้ายกับคำว่า 'แอปเปิ้ล' หรือ 'ทุ่งหญ้า' นั่นแสดงว่าตอนนี้เราสามารถแปลงคำต่าง ๆ เป็นเวกเตอร์ โดยเก็บความหมายของคำต่าง ๆ เอาไว้ได้แล้วด้วย
แล้วคุณคิดว่าคอมพิวเตอร์จะเข้าใจคำว่า 'หนู' ว่าอะไร หรือถามให้ชัดเจนขึ้นคือ คุณคิดว่าเวกเตอร์ของคำว่า 'หนู' นั้นน่าจะคล้ายกับเวกเตอร์ของคำว่าอะไรบ้าง
คำว่า 'หนู' อาจจะหมายถึงสัตว์ชนิดหนึ่ง หมายถึงคำแทนตัวของเด็กผู้หญิง หรือในกรณีของเราคือหมายถึงชื่อของนายกคนที่เราต้องการถามอายุ ดังนั้นถ้าเราพูดคำว่า 'หนู' ขึ้นมาลอย ๆ โดยไม่มีบริบท เราไม่มีทางรู้เลยว่า 'หนู' ในที่นี้หมายถึงอะไร
สำหรับ AI ก็เช่นกัน ไม่ว่าคุณจะหมายถึงหนูที่เป็นสัตว์ หนูที่ไว้ใช้แทนตัวเอง หรือหนูที่เป็นนายก เมื่อมันเห็นคำว่า 'หนู' มันก็จะทำได้แค่แปลงให้เป็นเวกเตอร์อันหนึ่ง ที่ไม่รู้ว่าหมายถึงหนูไหนกันแน่
ผมลองถาม ChatGPT ว่า
'หนูอายุเท่าไร'
คำตอบที่มันให้ผมคือ
'หนูอายุเท่าไหร่ หนูต้องเป็นคนบอกเองนะคะ 😊'
โอเค ชัดเลย มันเข้าใจว่าหนูนี้หมายถึงตัวคนถาม ไม่ใช่สัตว์ และไม่ใช่ชื่อนายก
เอาใหม่ ผมลองถาม ChatGPT ว่า
'หนูของผมอายุเท่าไร'
คำตอบที่มันให้ผมคือ
'ผมยังไม่รู้ข้อมูลเกี่ยวกับหนูของคุณเลยครับ เพื่อให้ตอบได้ คุณช่วยบอกเพิ่มได้ไหมว่าเป็น หนูชนิดไหน (เช่น หนูแฮมสเตอร์ หนูแกสบี้ หนูบ้าน ฯลฯ) หรือจะเล่าอาการ/ลักษณะให้ฟังเพิ่มเติมก็ได้ครับ แล้วผมจะช่วยประเมินอายุให้ใกล้เคียงที่สุด!'
คราวนี้มันคิดว่าเป็นสัตว์แฮะ
ใช่แล้วฮะ สิ่งที่ ChatGPT ทำคือการใช้บริบทหรือรอบ ๆ ข้างเพื่อมาตีความ ว่าคำว่าหนูในที่นี้นั้นหมายถึงหนูในความหมายไหนกันแน่ เหมือนกันที่คนเราทำนั่นแหละ คำถามที่สำคัญคือ แล้วเราจะสอนให้ AI พวกนี้รู้วิธีการอ่านบริบทรอบ ๆ ยังไงดีล่ะ
ขั้นแรก AI ต้องรู้ก่อนว่าคำคำนี้อยู่ตรงไหนในประโยค เพราะตำแหน่งของคำนั้นอาจบอกใบ้ความหมายได้ การพูดว่า 'ฉันกัดหมา' กับ 'หมากัดฉัน' นั้นมีความหมายต่างกันโดยสิ้นเชิง
เทคนิคที่นิยมใช้กันคือการสร้างเวกเตอร์ของตำแหน่งขึ้นมา เอาไปบวกกับเวกเตอร์ของคำศัพท์ ก็จะกลายเป็นเวกเตอร์ใหม่ที่เก็บข้อมูลทั้งตำแหน่งและความหมายของคำนั้น อย่างประโยค input ที่ว่า 'เสี่ยหนูอายุเท่าไร' นั้น ก็ควรจะแปลงได้เป็นเวกเตอร์ 4 ตัว ผมขอตั้งชื่อว่า e1 e2 e3 และ e4 ซึ่งแทนความหมายและตำแหน่งของคำว่า 'เสี่ย' 'หนู' 'อายุ' และ 'เท่าไร' ตามลำดับ
คราวนี้ ผมหยิบเมทริกซ์ที่ถูกสร้างขึ้นมาอย่างปราณีตขึ้นมาสามชื่อว่า WQ WK และ WV
- เอาเมทริกซ์ WQ ไปคูณกับ e1 e2 e3 และ e4 จะได้ออกมาเป็นเวกเตอร์ q1 q2 q3 และ q4 หรือเขียนรวบเป็นเมทริกซ์ Q = [q1, q2, q3, q4]
- เอาเมทริกซ์ WK ไปคูณกับ e1 e2 e3 และ e4 จะได้ออกมาเป็นเวกเตอร์ k1 k2 k3 และ k4 หรือเขียนรวบเป็นเมทริกซ์ K = [k1, k2, k3, k4]
- เอาเมทริกซ์ WV ไปคูณกับ e1 e2 e3 และ e4 จะได้ออกมาเป็นเวกเตอร์ v1 v2 v3 และ v4 หรือเขียนรวบเป็นเมทริกซ์ V = [v1, v2, v3, v4]
เอาเมทริกซ์ Q ไปคูณกับทรานสโพสของ K เอาไปหารด้วยค่าคงที่ จากนั้นเอาค่าที่ได้ออกมาไปสเกลค่าให้อยู่ในช่วง 0 ถึง 1 ด้วยฟังก์ชัน softmax แล้วเอาผลที่ได้มาคูณกับเมทริกซ์ V
แล้วก็ ตู้มมมมมมมมม ! ได้ออกมาเป็นก้อนอะไรสักอย่าง
โอเค ผมเข้าใจว่าคุณตามไม่ทันหรอกว่าเราทำอะไรไปบ้าง แต่เอาเป็นว่าหลัก ๆ มันคือการเอาเวกเตอร์ e1 e2 e3 และ e4 ที่แทนคำศัพท์ต่าง ๆ ที่เรามีตอนแรก มาคูณเมทริกซ์เยอะแยะไปหมดเลย แอบใส่ softmax ทีนึง แล้วก็คูณเมทริกซ์ต่ออีกที
ขั้นตอนที่ว่ามาทั้งหมด เขียนเป็นสูตรคณิตศาสตร์ได้ดังนี้ฮะ
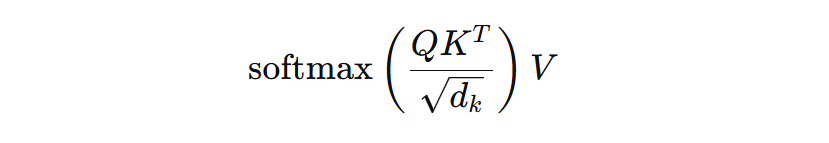
ผลลัพธ์ที่เราได้เป็นเมทริกซ์อันหนึ่งฮะ ซึ่งผมจะสมมติว่าให้มันมีขนาดเป็น 4×4 ก็แล้วกัน ความจริงเรากำหนดขนาดของมันได้แหละ แต่ในที่นี้ขอทำให้ขนาดของมันเท่ากับจำนวนคำในประโยคคำถามของเราเลยก็แล้วกัน เพื่อให้ง่ายต่อการตีความ
สมมติว่านี่คือเมทริกซ์ที่เราได้ฮะ
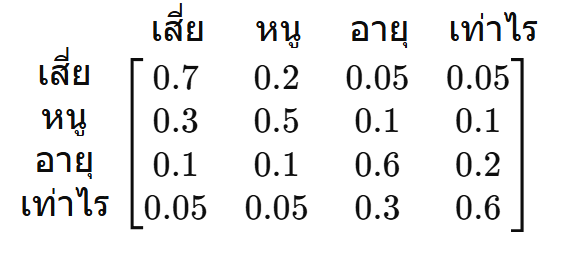
เมทริกซ์นี้ถูกเรียกว่าเมทริกซ์ A ซึ่งย่อมาจากคำว่า Attention ครับ เมทริกซ์นี้จะบอก AI ว่า ในการแปลความหมายของคำแต่ละคำนั้น ควรอิงจากคำไหนในประโยคมากน้อยแค่ไหน
ลองนึกดูดี ๆ สิครับ มนุษย์อย่างเรารู้ว่า 'หนู' ในประโยคนี้หมายถึงนายกเพราะเราเห็นคำว่า 'เสี่ย' ไม่ใช่จากคำว่า 'อายุ' หรือ 'เท่าไร' ถูกไหมฮะ
AI ก็เหมือนกัน มันเองก็ต้องการรู้ว่ามันควรตีความความหมายของ 'หนู' จากคำไหนดี และเมทริกซ์ Attention นี่แหละคือสิ่งที่บอกมัน
จากตัวอย่างที่ผมสมมติขึ้นมาจะเห็นในแถวที่ 2 ของเมทริกซ์ว่า การจะตีความคำว่า 'หนู' นั้น มันจะให้น้ำหนักกับคำว่า 'เสี่ย' ถึง 0.3 ซึ่งคือ 30% ให้น้ำหนักกับคำว่า 'หนู' ซึ่งคือตัวมันเอง 0.5 หรือ 50% และที่เหลืออีกคำละ 10% เท่านั้นเอง เพราะการจะตีความหมายของคำว่า 'หนู' นั้นแทบไม่ได้ต้องใช้คำว่า 'อายุ' หรือ 'เท่าไร' เลย
คำว่า 'เสี่ย' เองก็เช่นกัน การตีความมันแทบไม่ได้ใช้คำว่า 'อายุ' หรือ 'เท่าไร' ในขณะที่สองคำหลังนั้นใช้กันเองพอสมควร
สรุปง่าย ๆ ก็คือ เมทริกซ์ Attention ทำหน้าที่เหมือนตัวบอกความสนใจ จำลองสิ่งที่เราคิดในหัวเวลาอ่านและตีความคำต่าง ๆ ในบริบท เพื่อให้คอมพิวเตอร์เข้าใจความหมายของคำเหล่านั้นเหมือนที่มนุษย์เข้าใจนั่นเอง
จากนั้น AI มันจะเอาเมทริกซ์ Attention ไปคูณกับเมทริกซ์ V อีกที ออกมาเป็นเวกเตอร์ใหม่ 4 ตัวที่เรียกว่า e’1 e’2 e’3 และ e’4 เท่ากับจำนวนคำในประโยคนั่นแหละ เวกเตอร์แต่ละตัวก็แทนความหมายของคำแต่ละคำเช่นเดิม แต่คราวนี้มันจะไม่ได้แทนความหมายของคำนั้นแบบโดด ๆ อีกต่อไปแล้ว เพราะมันจะเก็บเอาการตีความบริบทจากคำรอบข้างเข้าไปด้วยแล้ว
เวกเตอร์ e2 ตอนแรกสุดที่ถูกใช้แทนคำว่า 'หนู' อาจจะเก็บความหมายของสัตว์สี่เท้าหางยาวตัวเล็ก แต่เวกเตอร์ e’2 ที่เราเพิ่มสร้างขึ้นมาเพื่อแทนคำว่า 'หนู' นี้จะเก็บความหมายของชื่อของนายกคนที่ 32 ของประเทศไทยแทนเรียบร้อยแล้ว
คุณจะเห็นว่าทั้งหมดนี้เรายังไม่ได้เริ่มกระบวนการตอบคำถามเลยนะ แค่หาวิธีทำให้ AI มันเข้าในความหมายของคำต่าง ๆ ในประโยคเท่านั้น ก็มีการคูณเมทริกซ์มากมายหลายครั้งไปหมด ตอนมันสร้างคำตอบจากคำถามที่เราใส่เข้าไปก็เต็มไปด้วยการคูณเมทริกซ์อีกเช่นกัน เพราะต้องไม่ลืมว่าสุดท้ายแล้วสิ่งที่มันตอบออกมาว่า 'ในปี พ.ศ. 2568 เขาอายุ 59 ปี' นั้นก็ไม่ใช่อะไรเลยนอกจากลำดับของเวกเตอร์หลาย ๆ ตัวเรียงต่อกัน แล้วจะสร้างเวกเตอร์พวกนั้นขึ้นมายังไงล่ะ ถ้าไม่ใช่การคูณเมทริกซ์
และทั้งหมดนี้ยังไม่นับว่าในความเป็นจริงแล้ว generative AI สักตัวมันไม่ได้ใช้เมทริกซ์ WQ WK และ WV แค่ชุดเดียว แต่อาจมีมากกว่านั้น เรียกว่า Multi-head Attention เพื่อที่ให้มันถึงเอาความหมายจากบริบทในหลาย ๆ แง่มุมเข้าไปช่วยกันตีความ ซึ่งก็จะทำให้ปริมาณของการคูณเมทริกซ์นั้นเพิ่มไปอีกเป็นหลายเท่า
เมทริกซ์ทั้งหลายพวกนี้ถูกเลือกมาด้วยกระบวนการทางคณิตศาสตร์ที่ซับซ้อน ซึ่งเรียกเป็นภาษาแบบคอมพิวเตอร์ว่าการ train model ซึ่งไม่ใช่สิ่งที่ผมตั้งใจจะเล่าตรงนี้ แต่อยากให้คุณเห็นว่าการเลือกเมทริกซ์พวกนี้ให้ถูกต้องนั้นสำคัญมาก ๆ เพราะมันคือสิ่งที่ชี้เป็นชี้ตายว่า AI ที่คุณใช้จะตอบคำถามคุณได้ดีมากน้อยแค่ไหน
รูปข้างล่างนี้คือกระบวนการทำงานทั้งหมด และที่เราคุยกันไปคือแค่ในกรอบสีแดงเท่านั้นเอง
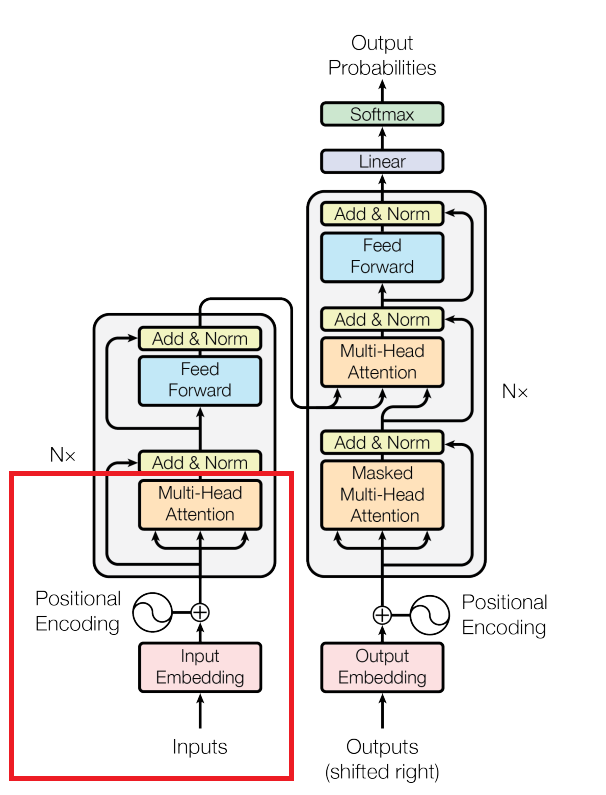
สรุปก็คือ ทุกครั้งที่คุณถามอะไรสักอย่างใน ChatGPT หรือ Gemini แล้วเห็นว่าระบบมันหมุน ๆ ก่อนจะส่งคำตอบออกมา ขอให้คุณรู้เอาไว้ว่าในช่วงเวลาชั่วอึดใจนั้น มีการคูณเมทริกซ์จำนวนมหาศาลเกิดขึ้นอยู่ เพื่อตีความสิ่งที่คุณถาม และสร้างออกมาเป็นคำตอบที่คุณน่าจะพอใจที่สุด
กระบวนการอ่านและสร้างคำตอบที่ใช้ Attention เป็นพื้นฐานแบบนี้นั้นเรียกว่า Transformer Model ฮะ มันถูกพัฒนาขึ้นมาโดย Google ในเปเปอร์ที่ตั้งชื่ออย่างเกรียน ๆ ว่า Attention Is All You Need ในปี 2017 และถือกันว่าเป็นโมเดลภาษาที่ดีที่สุดเท่าที่เรามีในปัจจุบัน

แน่นอนว่าวันหนึ่ง Transformer ก็อาจจะถูกล้มแชมป์ เหมือนที่มันเคยล้มโมเดลอื่นมาอีกทีเช่นกัน แต่ไม่ว่าโมเดลใหม่ที่มาแทน Transformer จะหน้าตาเป็นยังไง ตราบใดที่คอมพิวเตอร์ยังเก็บข้อมูลผ่าน array ของตัวเลขอยู่ ยังไงพื้นฐานของมันก็จะยังคงเป็นการคูณของเมทริกซ์อยู่แน่นอน แค่จะคูณเมทริกซ์อะไร คูณกันท่าไหน หรือเอาอะไรมาคูณกับอะไรให้ออกมาเป็นอะไรแค่นั้นเอง
ดังนั้นแม้ว่าการพูดว่าจะพูด 'การคูณเมทริกซ์' แย่งงานจะฟังดูเวอร์ไปสักหน่อย แต่ก็ยากจะปฏิเสธว่าไม่จริงใช่ไหมล่ะครับ
และเช่นเดิม ใครที่อยากสนับสนุนเพจเว็บไซต์ของเรา ให้ผลิตคอนเทนต์คณิตศาสตร์แบบนี้ต่อไป ก็สามารถสมัครเป็นสมาชิกรายเดือนได้โดยกดปุ่ม 'สมัครสมาชิก' ได้เลยนะฮะ
เอกสารอ้างอิง
https://arxiv.org/abs/1706.03762
https://www.youtube.com/watch?v=eMlx5fFNoYc
https://www.datacamp.com/tutorial/how-transformers-work
https://blogs.nvidia.com/blog/what-is-a-transformer-model/
https://arxiv.org/abs/2510.03989


